
 澳大利亚
澳大利亚 韩国
韩国 巴西
巴西 日本
日本 俄罗斯
俄罗斯 中国台湾
中国台湾 中国
中国 中国香港
中国香港 欧盟
欧盟 印度尼西亚
印度尼西亚 马来西亚
马来西亚 新加坡
新加坡 菲律宾
菲律宾 美国
美国 加拿大
加拿大 印度
印度 越南
越南 泰国
泰国 沙特阿拉伯
沙特阿拉伯大家好,我是麦洛克,今天我们讨论计量数据范畴里的两组平行对照设计样本量计算方法。
在临床实验中,研究者通常希望通过治疗药物与安慰剂或阳性对照物比较,来评价治疗药物的有效性和安全性。其典型的研究目的通常包括:
1) 治疗药物的疗效与安慰剂比较是否存在着有意义的临床差异;
2) 治疗药物的疗效是否不低于现有的公认有效药物;
3) 治疗药物的疗效是否优于现有的公认有效药物;
4) 治疗药物是否与现有公认有效药物有同等疗效。
两组平行对照设计常用以下两种设计方案:
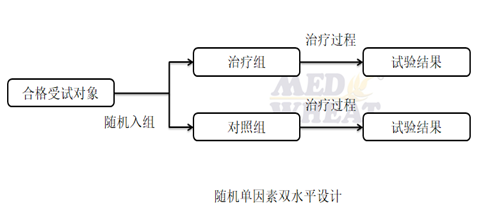
1.完全随机成组设计也称为完全随机单因素两水平设计,即将合格受试对象完全随机分为治疗组和对照组两组。
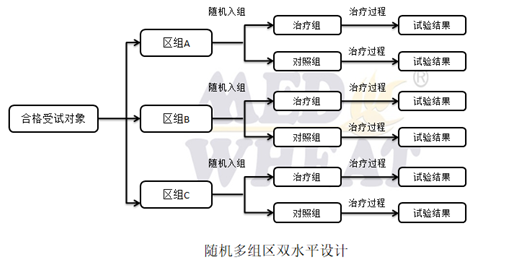
2. 随机区组设计它是将全部受试对象按某个或某些重要的属性(即区组因素,如多中心临床试验中的中心,血压的轻度、中度和重度等)分为若干个区组,在每个区组中随机分配两个受试因素。
我们说统计是工具,我们接下来看相关的统计公式:
1.差异性检验,两组病例数相等条件下,双侧检验的公式:
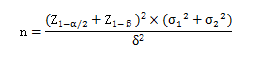
公式中:
1) n代表每组样本含量;
2) Z1-α/2和Z1-β需要查阅Z值表;
3) σ1代表第一组的标准差;
4) σ2代表第二组的标准差;
5) δ代表具有临床意义的两组差值。
2.差异性检验,两组病例数相等,单侧检验的公式:
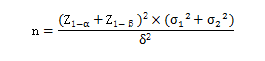
公式中:
1) n代表每组样本含量;
2) Z1-α和Z1-β需要查阅Z值表;
3) σ1代表第一组的标准差;
4) σ2代表第二组的标准差;
5) δ代表具有临床意义的两组差值。
3. 差异性检验,两组病例数不相等,双侧检验的公式:

公式中:
1) n1代表第一组样本含量;
2) Z1-α/2和Z1-β需要查阅Z值表;
3) σ1代表第一组的标准差;
4) σ2代表第二组的标准差;
5) δ代表具有临床意义的两组差值;
6) K代表两组病例数的比值;
7) n2代表第二组样本含量。4.差异性检验,两组病例数不相等,单侧检验的公式:
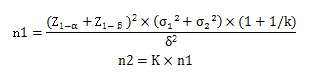
公式中:
1) n1代表第一组样本含量;
2) Z1-α和Z1-β需要查阅Z值表;
3) σ1代表第一组的标准差;
4) σ2代表第二组的标准差;
5) δ代表具有临床意义的两组差值;
6) K代表两组病例数的比值;
7) n2代表第二组样本含量。
5.非劣效性检验或优效检验,两组病例数相等的公式:

公式中:
1) n代表样本含量;
2) Z1-α和Z1-β需要查阅Z值表;
3) σ1代表第一组的标准差;
4) σ2代表第二组的标准差;
5) δ代表具有临床意义的低限或高限;
6) ε代表两组的实际差值。
6.非劣效性检验或优效检验,两组病例数不相等的公式:
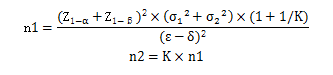
公式中:
1) n1代表第一组样本含量;
2) Z1-α和Z1-β需要查阅Z值表;
3) σ1代表第一组的标准差;
4) σ2代表第二组的标准差;
5) δ代表具有临床意义的低限或高限;
6) ε代表两组的实际差值;
7) n2代表第二组样本含量;
8) K代表两组病例数的比值。
7.等效性检验,两组病例数相等的公式:
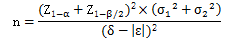
公式中:
1) n代表样本含量;
2) Z1-α和Z1-β/2需要查阅Z值表;
3) σ1代表第一组的标准差;
4) σ2代表第二组的标准差;
5) δ代表具有临床意义的低限或高限(低限或高限的绝对值相同);
6) ε代表两组的实际差值。
8.等效性检验,两组病例数不相等的公式:
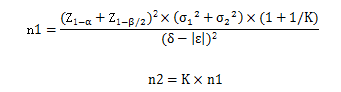
公式中:
1) n1代表第一组样本含量;
2) n2代表第二组样本含量;
3) Z1-α和Z1-β/2需要查阅Z值表;
4) σ1代表第一组的标准差;
5) σ2代表第二组的标准差;
6) δ代表具有临床意义的低限或高限(低限或高限的绝对值相同);
7) ε代表两组的实际差值;
8) K代表两组病例数的比值。
